Overview
In the dynamic landscape of cloud applications, resilience isn’t merely a desirable trait; it’s a necessity. The ability to withstand failures and recover from disruptions is crucial for ensuring business continuity. However, the complexity of modern cloud applications makes predicting and preventing failures challenging. To tackle this challenge head-on, more and more companies are turning to Chaos Engineering.
Chaos Engineering is a disciplined approach to identifying failures before they result in outages. By proactively testing how a system responds under stress, you can identify and fix failures before they become headline news. In essence, Chaos Engineering involves breaking things intentionally to learn how to build more resilient systems.
Azure Chaos Studio is a fully managed service that enables engineers to orchestrate chaos experiments as a means of validating resilience. It provides a structured framework for injecting real-world faults into both application and infrastructure, allowing engineers to uncover weaknesses before they affect customers. Azure Chaos Studio is built on the core principles of Chaos Engineering, offering a systematic approach to resilience validation.
Why use Azure Chaos Studio?
There are several reasons why you should use Azure Chaos Studio:
- Real-world Validation: Replicate and understand real incidents for better post-incident recovery.
- Business Continuity: Conduct drills for disaster recovery and ensure critical data preservation.
- High Availability Testing: Validate resilience against outages, stress events, and configuration errors.
- Performance Benchmarking: Develop benchmarks for capacity planning and ensure smooth cloud migration.
- Security Confidence: Identify vulnerabilities proactively and fortify against potential exploits.
Chaos Scenarios
Azure Chaos Studio facilitates diverse resilience validation scenarios, categorized into two types: shift right, which involves real or simulated customer traffic in production or preproduction environments, and shift left, conducted in development or shared test environments without actual customer traffic.
This tool is employed for various chaos engineering scenarios, including reproducing incidents for better understanding, preparing for major events, conducting business continuity drills, running high-availability tests, developing performance benchmarks, planning capacity, stress testing, and ensuring the resilience of migrated services. Ad-hoc chaos experiments initially build resilience, followed by continuous validation through chaos experiments integrated into deployment pipelines to prevent regression.
Chaos Experiments
Experiments are the heart of Azure Chaos Studio; an orchestrated approach to injecting real-world faults into an application for the sake of resilience. An experiment, depicted as an Azure resource, is intricately divided into two sections: selectors and logic.
Selectors serve as precision tools, strategically grouping target resources for fault injection, exemplified by scenarios like the AllNonProdWestEuropeVMs selector. These selectors enable engineers to target specific groups of resources, providing a nuanced approach to fault injection.
On the other hand, the logic section orchestrates chaos with structured sequencing—steps, branches, and actions — forming a narrative that guides disruptions through various phases and granular actions, offering a purposeful exploration of an application’s resilience. Specifically, the logic section is composed of steps, branches, and actions.
Steps are the building blocks of an experiment, each containing a set of branches that are executed in parallel. Steps are executed sequentially, and the experiment proceeds to the next step only after all branches in the current step have been completed. These steps provide a structured framework, ensuring a systematic and logical approach to introducing disruptions.
Branches are the parallel narratives of an experiment, each containing a set of actions.
Actions are the granular units of an experiment. An action is either a fault or a time delay.
Time delays are the pauses between actions, allowing the experiment to simulate real-world scenarios. For example, a time delay can be used to simulate the time it takes for a service to recover from a fault.
Faults are the actual disruptions injected into the target resources for a specified period, causing failures like network latency, CPU spikes, process termination, and more. There are two types of faults: service-based and agent-based.
Service-based faults operate directly on Azure resources without additional installation or instrumentation. Examples include actions like rebooting an Azure Cache for a Redis cluster or introducing network latency to Azure Kubernetes Service pods.
Agent-based faults require the installation of the Chaos Studio agent and delve into the intricacies within virtual machines (VMs) or virtual machine scale sets. These faults allow for in-guest failures, such as applying virtual memory pressure or terminating a specific process.
More about the available faults and actions in general can be found here.
Targets & Capabilities
The precision in chaos execution lies in the careful selection of targets and the capabilities assigned to them. Azure Chaos Studio offers various mechanisms for defining targets and capabilities, ensuring that chaos is directed with purpose.
In scenarios where a specific set of resources needs to be targeted for a particular fault, list-based manual target selection shines. It allows for the precise selection of onboarded targets, ensuring that chaos is applied with precision.
For a more dynamic approach, query-based dynamic target selection leverages Kusto Query Language (KQL). This mechanism enables chaos engineers to define queries that dynamically select onboarded targets based on various parameters like resource type, region, or name.
Not all faults need to be applied universally. Target scoping allows engineers to further refine the impact of chaos by targeting specific functionality within Azure resources. This fine-tuning ensures that disruptions are applied only where needed.
Permissions & Security
Azure Chaos Studio implements a robust permission and security model to safeguard against unintentional or malicious fault injection.
Azure Resource Manager (ARM) permissions play a pivotal role in controlling the chaos. Chaos engineers must have appropriate permissions to create, update, start, cancel, delete, or view an experiment. These permissions are assigned at a granular level, ensuring controlled access to chaos orchestration.
Every chaos experiment in Azure Chaos Studio is associated with a managed identity, either system-assigned or user-assigned. This identity is crucial for executing faults securely. Engineers can choose to enable custom role assignment, allowing Azure Chaos Studio to create and assign custom roles containing necessary experiment action capabilities.
Before chaos can be injected into a resource, the resource must undergo onboarding to Chaos Studio as a target. This process involves enabling specific capabilities for the resource, ensuring that only authorized faults can be executed. Targets and capabilities act as the first line of defense against accidental or malicious fault injection.
Private Networking
While chaos engineering demands controlled disruption, it also requires a secure and isolated environment. Azure Chaos Studio introduces features for private networking, allowing chaos engineers to orchestrate controlled chaos within the confines of a virtual network. Azure Chaos Studio supports virtual network injection, enabling private links for both service-direct and agent-based experiments. This feature ensures that chaos experiments are executed within a private network, minimizing exposure to external networks. However, not all resource types are eligible for virtual network injection at the moment.
Example
Let’s take a look at an example experiment to understand how Azure Chaos Studio works. Our architecture consists of the following resources:
- one Ubuntu virtual machine
- one Ubuntu virtual machine scale set with two instances
- one App Service
- one Key Vault
In the Chaos Studio portal we can see our currently disabled targets:
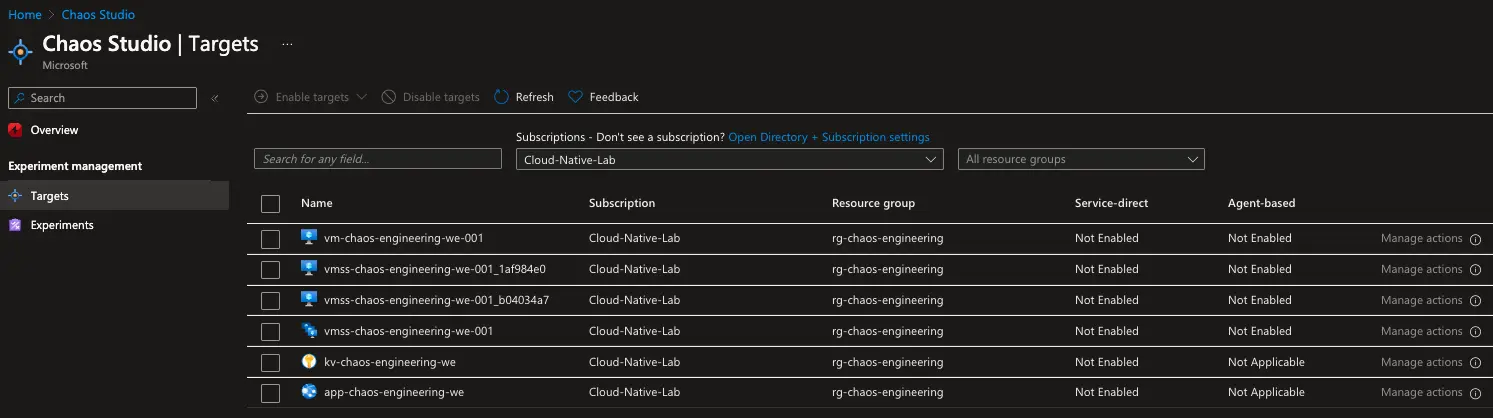
We can enable these targets by clicking on the Enable targets button.
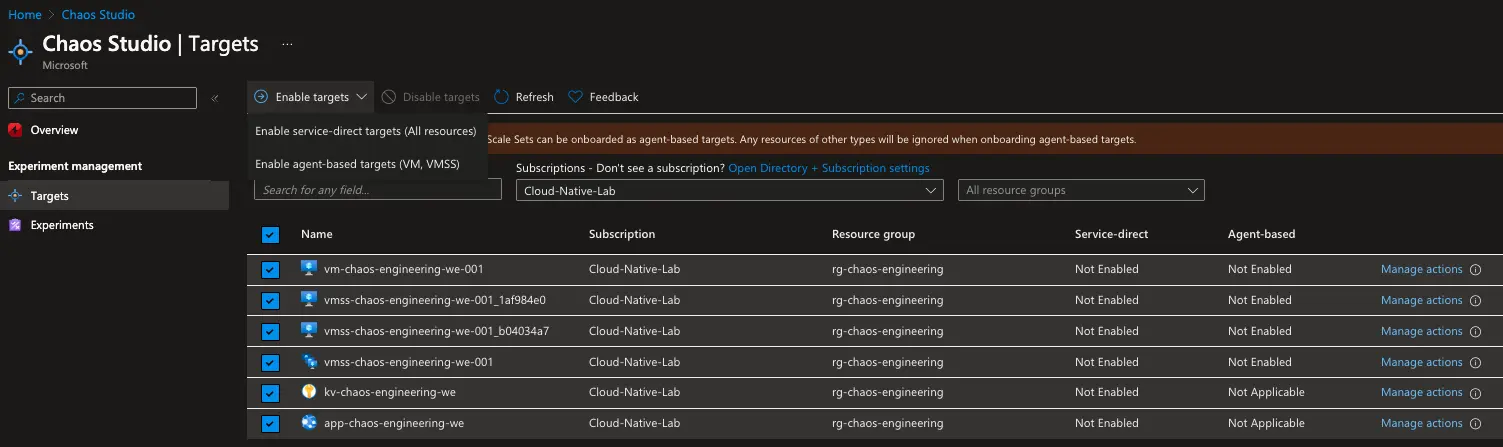
All of our resources can be enabled as service-based targets, whereas only the virtual machine and virtual machine scale set can be enabled as agent-based targets. That is because an agent (Chaos Studio agent) needs to be installed on the virtual machine and the virtual machine scale set to be able to inject agent-based faults.
To enable the agent-based targets we need to create a user-assigned managed identity and assign it to them. This identity will be used by the Chaos Studio agent to execute the agent-based faults.
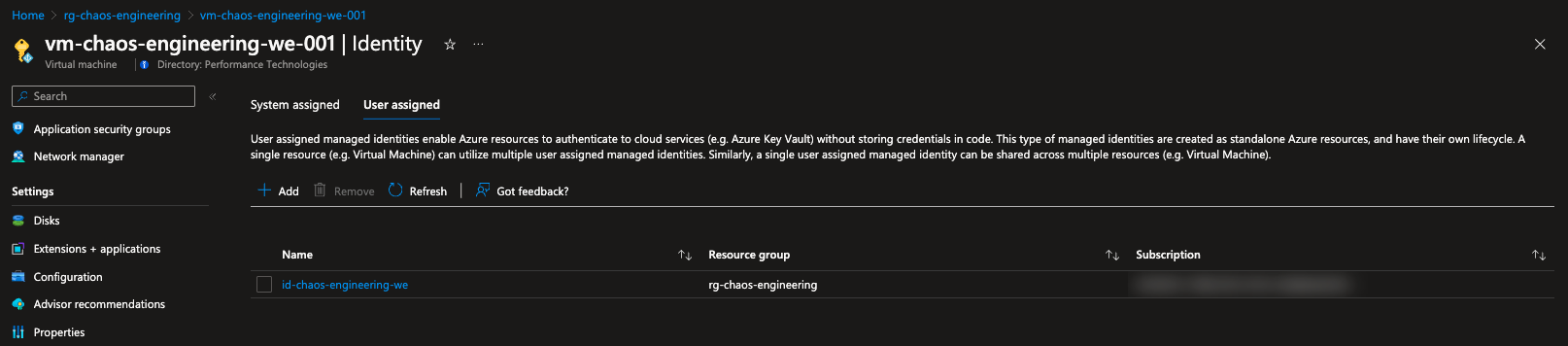
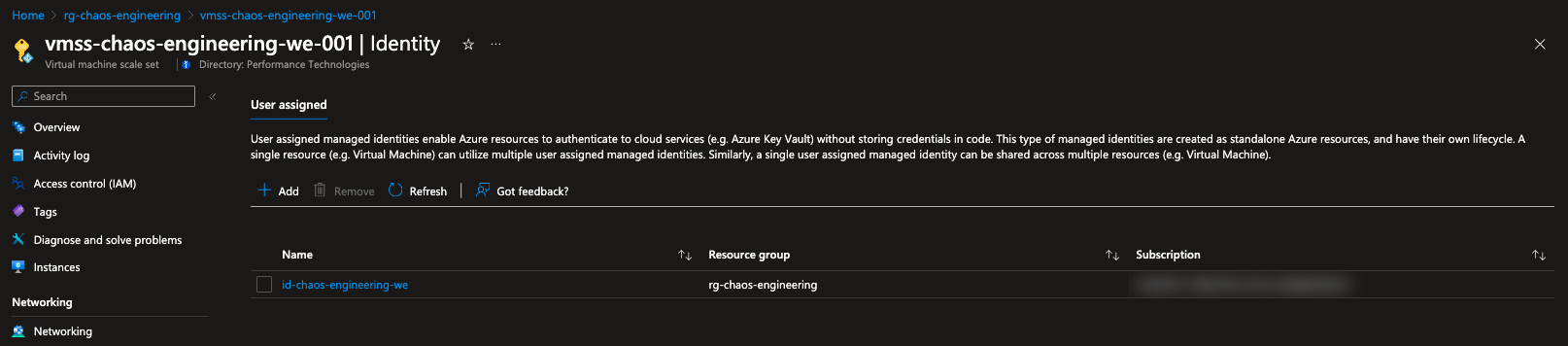

Since we have enabled our targets, we can now create an experiment.
As mentioned before, an experiment is composed of selectors and logic. The selectors are used to select the targets that we want to inject faults into. The logic is used to define the steps, branches, and actions of the experiment. Also, each experiment has an identity associated with it. This identity is used to execute the experiment and needs to have the appropriate permissions to do so.
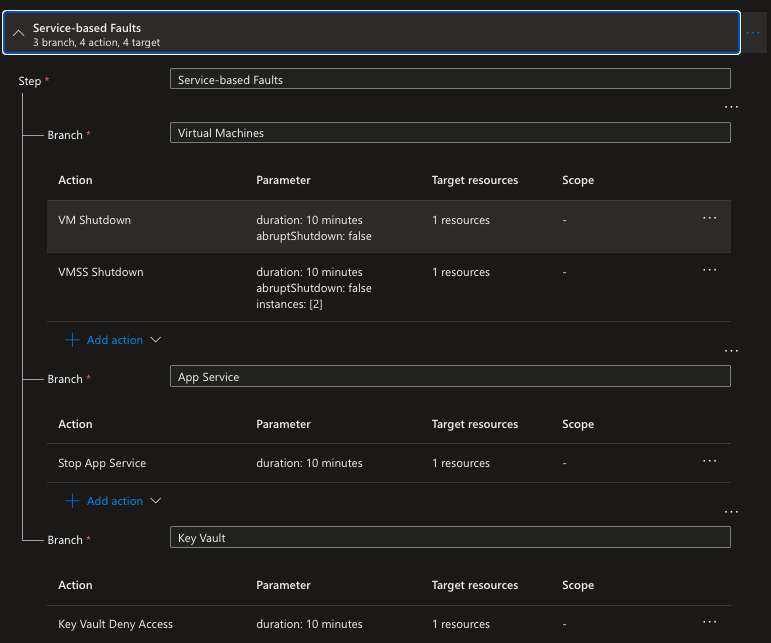
We are going to create an experiment with two steps named Service-based Faults and Agent-based Faults. The first step needs to be completed successfully before the second step can be executed.
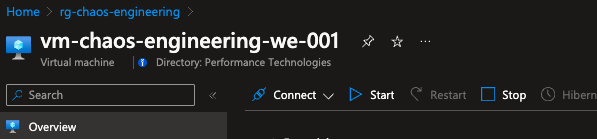
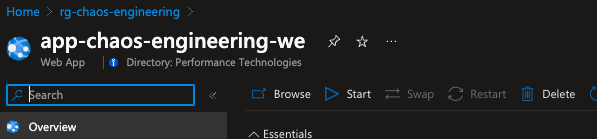
The service-based faults step has three branches that execute in parallel. The first branch has two actions and essentially shutdowns for ten minutes the virtual machine and then the virtual machine scale set. The second branch stops the app service for ten minutes. The third branch stops the key vault from accepting requests for ten minutes.
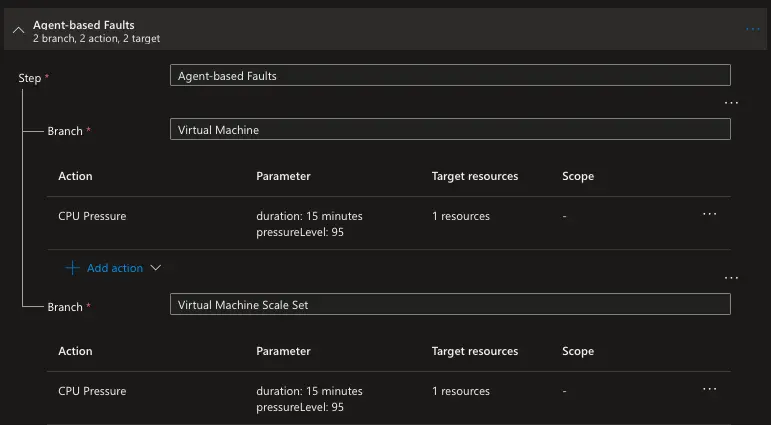
The agent-based faults step has two branches that execute in parallel. The first branch has one action which applies CPU pressure to the virtual machine for fifteen minutes. The second branch has one action which applies CPU pressure to the virtual machine scale set for fifteen minutes.
Here is the overview of the experiment:

When we create the experiment, a new resource is created in our resource group. This resource is of the type Chaos Studio Experiment and has the same name as the experiment.
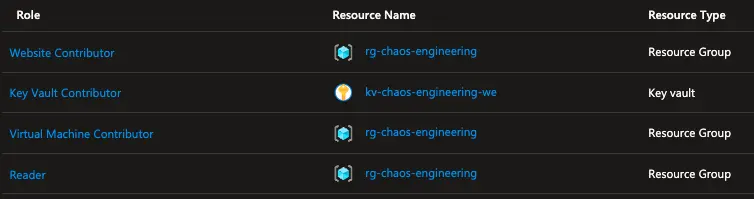
For the experiment to execute successfully, we need to assign the appropriate permissions to the experiment identity. Here are some of the recommended permissions based on actions taken:

So, let’s go ahead and assign the following roles to the experiment identity:
Keep in mind:
On either Linux or Windows VMs, the system-assigned managed identity for the experiment must be granted the Reader role on the VM. Seemingly elevated roles like Virtual Machine Contributor don’t include the */Read operation that’s necessary for the Chaos Studio agent to read the microsoft-agent target proxy resource on the VM.
Here is a recap of what we have done so far:
- We created a user-assigned managed identity and assigned it to the agent-based targets (vm and vmss)
- We enabled our targets for both service-based and agent-based faults
- Then we created an experiment with two steps and assigned its identity the appropriate roles
Now we can start the experiment.
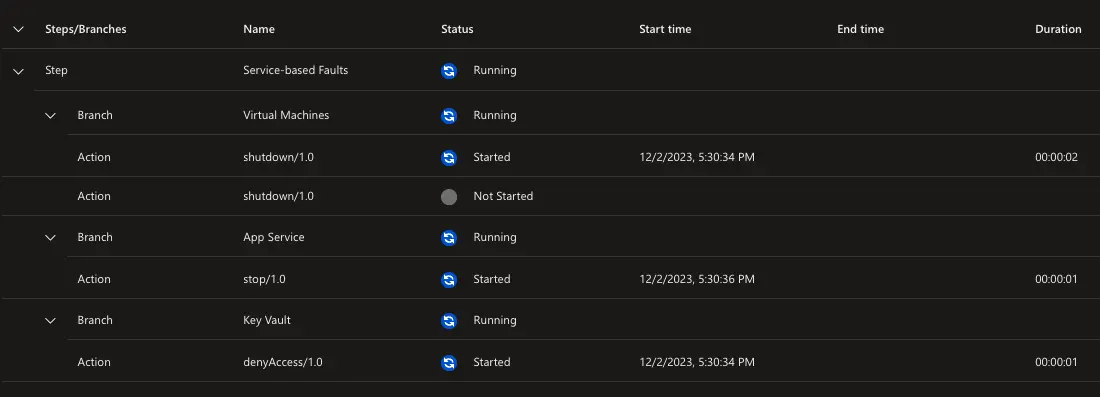
We can see that the experiment is running and that the first step is in progress.
Below are some screenshots of the resources during the experiment:

Summary
Azure Chaos Studio serves as a pivotal tool in the realm of Chaos Engineering, offering a structured platform for deliberate fault injection to enhance the resilience of cloud applications.



Leave a comment