General
With the rise of microservices, distributed architectures, and the diverse array of programming languages employed in modern applications, the limitations of existing data interchange formats became apparent. The need for a more efficient, compact, and language-agnostic solution led to the creation of Protocol Buffers.
Definition
Protocol Buffers, also known as protobuf, is a language-agnostic binary serialization format developed by Google. It enables efficient serialization and deserialization of structured data, making it ideal for scenarios where performance and data size are critical.
Benefits
-
Efficient Serialization: Protocol Buffers use a binary serialization format, resulting in smaller message sizes compared to text-based formats like JSON. This efficiency is crucial for reducing bandwidth usage and improving data transfer speed.
-
Language-Agnostic: Protocol Buffers provide language-agnostic data serialization, enabling seamless communication between applications implemented in different programming languages. This makes them an ideal choice for microservices architectures.
-
Schema Evolution: Protocol Buffers support schema evolution, allowing developers to make changes to the data structure without breaking compatibility. New fields can be added, and optional fields can be introduced, providing flexibility for evolving software systems.
-
Code Generation: The use of a defined schema allows for automatic code generation in various programming languages. This feature simplifies the development process by creating native objects that can be easily integrated into the application code.
-
Performance: Due to their binary nature and efficient serialization, Protocol Buffers contribute to improved performance, making them suitable for high-throughput applications. The reduced size of serialized data also leads to faster data transmission.
-
Backward and Forward Compatibility: Protocol Buffers are designed to be backward and forward-compatible. This means that clients using an older version of the schema can still deserialize data produced by a newer version, and vice versa, ensuring smooth transitions during software updates.
-
Interoperability: The ability to generate code in multiple languages enhances interoperability between different components of a distributed system. Whether it’s communication between microservices or data interchange between backend and frontend components, Protocol Buffers facilitate seamless integration.
Applications
-
Microservices Architectures: Protocol Buffers are widely adopted in microservices architectures for efficient communication between services. The compact binary format contributes to lower latency and improved performance.
-
gRPC (Remote Procedure Call): gRPC, an open-source RPC (Remote Procedure Call) framework developed by Google, utilizes Protocol Buffers as its default serialization mechanism. gRPC allows seamless communication between services, offering features like bidirectional streaming and pluggable authentication.
-
Web APIs: Many web APIs leverage Protocol Buffers to transmit data efficiently between clients and servers. The reduced payload size is particularly advantageous in scenarios with limited bandwidth or mobile applications.
-
Message Queue Payloads: Protocol Buffers find applications in message queues, where compact serialization is crucial for minimizing the overhead of transmitting messages between distributed systems.
-
Data Interchange Between Languages: The language-agnostic nature of Protocol Buffers makes them suitable for scenarios where applications written in different programming languages need to exchange data. This is especially relevant in heterogeneous technology stacks.
-
Big Data Processing: Protocol Buffers are employed in big data processing pipelines for serializing and deserializing data efficiently. Their compact format is beneficial when dealing with large datasets.
-
IoT (Internet of Things): In IoT applications, where devices may have limited processing power and bandwidth, Protocol Buffers provide an efficient means of serializing and transmitting data.
-
Communication Between Backend and Frontend: Protocol Buffers are utilized in scenarios where backend systems communicate with frontend applications. The ability to generate code in multiple languages facilitates seamless integration into diverse client applications.
-
Distributed Systems: Any scenario involving communication between distributed systems, such as databases, caches, or other networked components, can benefit from Protocol Buffers’ efficient serialization and schema evolution capabilities.
These use cases showcase the versatility of Protocol Buffers in addressing communication challenges across various domains and technologies.
Usage
General Flow
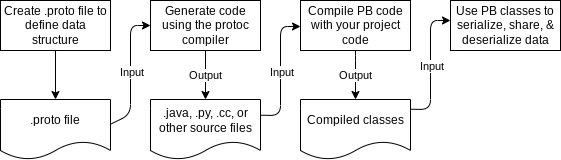
File Organization
Protocol Buffers (Protobuf) use .proto files to define the structure of messages. These files contain the schema definition for your data.
Compiler (protoc)
To work with Protobuf, you use the Protocol Buffers Compiler (protoc). It takes your .proto files and generates code in your desired programming language, provided that you have the corresponding Protobuf plugin installed depending on the language you are using.
For details on how to install protoc, refer to the Protocol Buffers Installation documentation.
For Mac users, you can install the compiler using Homebrew:
brew install protobufMajor Components
NOTE: This guide uses the latest version of Protocol Buffers, proto3. For details on the differences between proto2 and proto3, refer to the Language Guide.
Messages
Messages are the fundamental building blocks of a .proto file. They define structured data with fields.
message Person {
int32 id = 1;
string name = 2;
string email = 3;
}In the example above:
- The
syntaxdeclaration specifies the version of the Protocol Buffers syntax in use (proto3 in this case). - The
messagekeyword defines a message type named Person. Inside the message, fields are defined with their data type and a unique field number (tag) which is used to identify your fields in the message binary format.
Scalar Value Types
Protobuf supports primitive data types such as integers, booleans, and floats. Refer to the Scalar Value Types documentation for the full list.
Default Values
If a field is not set, it will have a default value. For example, the default value for a string field is the empty string "".
Enums
Enums are used to define a set of named integer constants. For example:
enum COLOUR {
RED = 0;
GREEN = 1;
BLUE = 2;
}Reserved Values
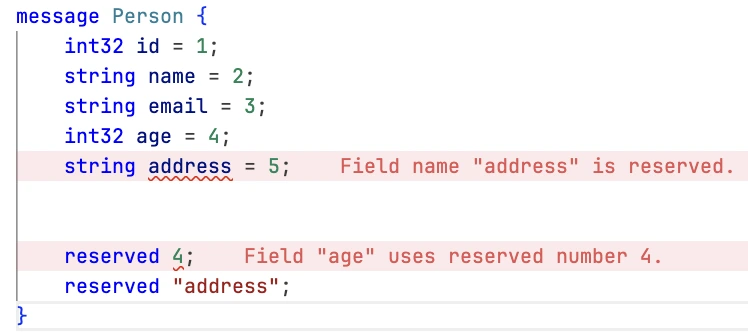
If you update a message type by entirely deleting a field, or commenting it out, future developers can reuse the field number when making their own updates to the type. This can cause severe issues, as described in Consequences of Reusing Field Numbers. To make sure this doesn’t happen, add your deleted field number to the reserved list. To make sure JSON and TextFormat instances of your message can still be parsed, also add the deleted field name to a reserved list. The protocol buffer compiler will complain if any future developers try to use these reserved field numbers or names.
message Person {
int32 id = 1;
string name = 2;
string email = 3;
reserved 4, 5, 6 to 10;
reserved "address";
}In the example above, we have reserved field numbers 4 to 10 and the field name address. So, if any developer attempts to use these numbers or names in the future, the compiler will issue a warning.
Nested Types
You can define and use message types inside other message types. These are called nested types.
message Person {
int32 id = 1;
string name = 2;
message PhoneNumber {
string number = 1;
}
repeated PhoneNumber phones = 3;
}Here we have a nested type PhoneNumber which is used in the phones field. You can also see the repeated keyword which indicates that the field is a repeated field. This is similar to an array or list.
Oneof
The oneof keyword is used to specify that only one of the fields in the group can be set at a time. For example:
message Person {
int32 id = 1;
string name = 2;
oneof address {
string home_address = 4;
string work_address = 5;
}
}So, if we set the home_address field, the work_address field will be cleared as:
If multiple values are set, the last set value as determined by the order in the proto will overwrite all previous ones.
Maps
Maps are used to represent repeated fields of key-value pairs.
message Person {
int32 id = 1;
string name = 2;
enum Relationship {
FATHER = 0;
MOTHER = 1;
SIBLING = 2;
}
map<int32, Relationship> family = 3;
}In the example above, we have a map called family which maps an integer key that represents the person’s ID to a Relationship enum value.
Packages
Packages are used to organize your .proto files into namespaces. They are similar to Java packages or C# namespaces.
syntax = "proto3";
package com.example;
...For a detailed explanation of packages, refer to the Packages documentation.
Imports
Imports are used to import definitions from other .proto files. For example:
import "google/protobuf/timestamp.proto";
import "person.proto";
...Example
Now that we have covered the basics, let’s look at an example to see how all these concepts come together.
For those of you who don’t know or haven’t visited the site’s Music Corner yet, I am a big fan of classical music.
So, let’s create a simple library for classical music. The main entities we will be working with are song, composer, and library.
The language we will be using is Go, but you can use any language you want.
Step 1: Setup Workspace
First of all, you need to make sure that you have both the Go and Protocol Buffers compilers installed on your machine.
Then, we need to create a workspace for our project. Let’s call it protobuf.
mkdir protobuf && cd protobuf
touch main.go
go mod init github.com/christosgalano/protobuf # replace with your own github name
mkdir model && touch model/music.protoStep 2: Define our Model
// File: music.proto
syntax = "proto3";
option go_package = "github.com/christosgalano/protobuf/model";
message Song {
int32 id = 1;
string name = 2;
Composer composer = 3;
}
message Composer {
enum Period {
PERIOD_UNSPECIFIED = 0; // Default value when period is not known or not set.
PERIOD_MEDIEVAL = 1; // Medieval period (approx. 500-1400), known for use of modes and monophonic texture.
PERIOD_RENAISSANCE = 2; // Renaissance period (approx. 1400-1600), known for focus on harmony and development of tonal structure.
PERIOD_BAROQUE = 3; // Baroque period (approx. 1600-1750), known for complex musical ornamentation.
PERIOD_CLASSICAL = 4; // Classical period (approx. 1750-1830), known for clarity, balance, and transparency of sound.
PERIOD_ROMANTIC = 5; // Romantic period (approx. 1830-1900), known for expressive, emotive music.
PERIOD_TWENTIETH_AND_TWENTY_FIRST_CENTURY = 6; // 20th and 21st Century, characterized by a wide range of styles and approaches.
}
int32 id = 1;
string name = 2;
Period period = 3; // Default will be PERIOD_UNSPECIFIED
repeated Song songs = 4;
}
message Library {
int32 id = 1;
string name = 2;
repeated Song songs = 3;
}Let’s go through the above code and see what we have done.
First of all, we define the syntax we are using, which is proto3 in our case.
Then, we define the package name. This is the name of the go package that will be generated by the compiler.
Then, we define our message types. We have three message types: Song, Composer, and Library.
Our Song message type has three fields: id, name, and composer. The composer field is of type Composer, which is another message type.
The Composer message type has four fields: id, name, period, and songs. The period field is of type Period, which is an enum type. The songs field is a repeated field of type Song. I also added a comment to each enum value to describe each period for you music fans out there.
Finally, our Library message type has three fields: id, name, and songs. The songs field is again a repeated field of type Song.
Step 3: Generate Code
Now that we have defined our model, we need to generate the code for our Go application.
First, we need to install the Go plugin for Protocol Buffers:
go install google.golang.org/protobuf/cmd/protoc-gen-goThen, we can generate the code by compiling our .proto file:
protoc --go_out=. --go_opt=paths=source_relative model/music.protoThis will generate a music.pb.go file in our model directory.
Step 4: Implement our Application
Now that we have generated the code, we can start implementing our demo application.
// File: main.go
package main
import (
"encoding/json"
"fmt"
"log"
"os"
"google.golang.org/protobuf/proto"
"github.com/christosgalano/protobuf/model"
)
func main() {
// Create a new composer
Bach := &model.Composer{
Id: 1,
Name: "Johann Sebastian Bach",
Period: model.Composer_PERIOD_BAROQUE,
}
fmt.Println(Bach)
// Create a new song (personal favorite)
Chaconne := &model.Song{
Id: 1,
Name: "Chaconne from Partita No. 2 in D Minor, BWV 1004",
Composer: Bach,
}
fmt.Println(Chaconne)
// Encode the song using protobuf
data, err := proto.Marshal(Chaconne)
if err != nil {
log.Fatalf("proto marshaling error: %v", err)
}
fmt.Printf("Protobuf data (size: %d): %v\n\n", len(data), data)
// Write to file
if err := os.WriteFile("chaconne.protobuf", data, 0644); err != nil {
log.Fatalf("error writing chaconne.protobuf: %v", err)
}
// Encode the song using JSON for comparison
data, err = json.Marshal(Chaconne)
if err != nil {
log.Fatalf("json marshaling error: %v", err)
}
fmt.Printf("JSON data (size: %d): %v\n\n", len(data), data)
// Write to file
if err := os.WriteFile("chaconne.json", data, 0644); err != nil {
log.Fatalf("error writing chaconne.json: %v", err)
}
// Read from file
data, err = os.ReadFile("chaconne.protobuf")
if err != nil {
log.Fatalf("error reading Chaconne.protobuf: %v", err)
}
// Decode the song using protobuf
c := &model.Song{}
if err := proto.Unmarshal(data, c); err != nil {
log.Fatalf("proto unmarshaling error: %v", err)
}
fmt.Printf("Chaconne: %+v\n\n", c)
}First, we create a new composer and a new song. Then, we encode the song using protobuf and write it to a file. We also encode the song using JSON for comparison and write it to a file. Finally, we read the protobuf file, decode it, and print the decoded song.
Here is the hexadecimal comparison between the protobuf and JSON encodings:

As you can see, the protobuf encoding is much more compact than the JSON encoding. We can easily see the difference in size:

Best Practices
- Clients and servers are never updated simultaneously. Avoid making breaking changes assuming perfect synchronization. There’s always a risk of rollbacks, impacting the compatibility between client and server.
- Never reuse a tag number. It disrupts deserialization and can lead to issues even if you believe the field is unused.
- When deleting a field, reserve its tag number to prevent accidental reuse in the future.
- Similar to fields, reserve numbers for deleted enum values to avoid unintended reuse.
- Avoid changing the type of a field, as it can disrupt deserialization. Refer to protobuf docs for acceptable cases.
- Never add a required field. Make fields optional or repeated to ensure flexibility.
- Avoid creating messages with an excessive number of fields. Large messages can lead to compilation issues and increased memory usage.
- Include a default
FOO_UNSPECIFIEDvalue as the first in enums to handle unknown values gracefully. - Embed common types like
durationandtimestampto leverage well-known functionality. - Place widely used message types in separate files to facilitate external usage without introducing unnecessary dependencies.
- Adhere to the style guide for generated code, ensuring compatibility with other code standards.
- Avoid using text format for interchange, as it can lead to deserialization issues when renaming or adding fields.
- Serialization stability is not guaranteed across builds. Avoid relying on it for purposes like building cache keys.
- Avoid using language keywords for field names to prevent conflicts during serialization and access.
Summary
In summary, Protocol Buffers are a great way to serialize and deserialize data. They are language-agnostic, efficient, and easy to use. These benefits make them ideal for scenarios where performance and data size are critical, such as microservices architectures, web APIs, and big data processing pipelines.


Leave a comment